本地英文版地址: ../en/query-dsl-function-score-query.html
function_score 允许你修改查询检索到的文档的分数。
例如,如果一个评分函数的计算开销很大,并且它足以计算经过筛选的一组文档的分数,那么这就很有用了。
要使用 function_score,用户必须定义一个查询和一个或多个函数,这些函数为查询返回的每个文档计算一个新分数。
function_score 只能用于一个函数,如下所示:
GET /_search
{
"query": {
"function_score": {
"query": { "match_all": {} },
"boost": "5",
"random_score": {},
"boost_mode":"multiply"
}
}
}
|
受支持的函数列表请参考 函数评分。 |
此外,几个功能可以组合。在这种情况下,我们可以选择只在文档匹配指定的 filter 查询时应用该函数。
GET /_search
{
"query": {
"function_score": {
"query": { "match_all": {} },
"boost": "5",
"functions": [
{
"filter": { "match": { "test": "bar" } },
"random_score": {},
"weight": 23
},
{
"filter": { "match": { "test": "cat" } },
"weight": 42
}
],
"max_boost": 42,
"score_mode": "max",
"boost_mode": "multiply",
"min_score" : 42
}
}
}
|
整个查询的提高(boost)。 |
|
|
受支持的函数列表请参考 函数评分。 |
每个函数的 filter 查询产生的分数并不重要。
如果函数中没有给出任何 filter,这相当于指定 "match_all": {}。
首先,每个文档由定义的函数评分。
参数 score_mode 指定如何组合计算出的分数:
|
|
分数相乘(默认) |
|
|
分数相加,求和 |
|
|
分数的平均值 |
|
|
应用第一个具有匹配 filter 的函数 |
|
|
取分数最大值 |
|
|
取分数最小值 |
因为分数可以在不同的范围内(例如,衰减函数(decay function)在0到1之间,而 field_value_factor 是任意的),而且有时函数对分数的不同影响是可取的,所以可以使用用户定义的 weight(权重) 来调整每个函数的分数。
weight可以在 functions数组(上面的例子)中按每个函数定义,并与相应函数计算的分数相乘。
如果给定 weight 时没有任何其他函数声明,weight 就会作为一个函数返回weight 。
如果 score_mode 被设置为 avg,则单个分数将被 weighted(加权) 平均。
例如,如果两个函数返回 1 和 2 分,它们各自的权重分别为 3 和 4,那么它们的得分将合并为 (1*3+2*4)/(3+4) 而不是 (1*3+2*4)/2。
通过设置 max_boost 参数,可以限制新的分数不超过某个限制。
max_boost 的默认值是 FLT_MAX。
新计算的分数与查询的分数相结合。 参数 boost_mode 定义了如何操作:
|
|
查询分数和函数分数相乘(默认) |
|
|
只使用函数分数,而忽略查询分数 |
|
|
查询分数和函数分数相加 |
|
|
平均值 |
|
|
查询分数和函数分数的最大值 |
|
|
查询分数和函数分数的最小值 |
默认情况下,修改分数不会改变匹配的文档。
要排除不满足某个分数阈值的文档,可以将参数 min_score 设置为所需的分数阈值。
要让 min_score 起作用,需要对查询返回的所有文档进行评分,然后逐一过滤掉。
-
script_score -
weight -
random_score -
field_value_factor -
衰减函数 (decay function):
gauss,linear,exp
script_score 函数允许包裹另一个查询,并使用脚本表达式使用从文档中的其他 数值(numeric) 字段值派生的计算定制该查询的评分。
这里是一个简单的例子:
GET /_search
{
"query": {
"function_score": {
"query": {
"match": { "message": "elasticsearch" }
},
"script_score" : {
"script" : {
"source": "Math.log(2 + doc['likes'].value)"
}
}
}
}
}
在 Elasticsearch 中,所有文档的评分都是一个 32 位的浮点数。
如果 script_score 函数生成了一个精度更高的分数,那么它将被转换为最接近的 32 位浮点数。
同样,分数必须是非负的。 否则,Elasticsearch 返回一个错误。
在不同的脚本字段值和表达式之上,可以使用 _score 脚本参数根据包裹的查询来检索分数。
脚本编译被缓存以更快地执行。
如果脚本有需要考虑的参数,最好重用同一个脚本,并为其提供 params(参数):
GET /_search
{
"query": {
"function_score": {
"query": {
"match": { "message": "elasticsearch" }
},
"script_score" : {
"script" : {
"params": {
"a": 5,
"b": 1.2
},
"source": "params.a / Math.pow(params.b, doc['likes'].value)"
}
}
}
}
}
请注意,与 custom_score 查询不同,查询的分数会乘以脚本评分的结果。
如果你希望禁止这种情况,请设置 "boost_mode": "replace"。
weight 分数允许你将分数乘以指定的 weight 值。
这有时是需要的,因为在特定查询上设置的 boost(提升)值 被归一化了,而对于这个评分函数却没有。
number 值的类型是 float。
"weight" : number
random_score 生成从 0 到 1 (不包括1) 均匀分布的分数。
默认情况下,它使用内部 Lucene 文档 id 作为随机数种子(seed),这非常有效,但不幸的是不可再现的,因为文档可能会被合并而重新编号。
如果你希望分数是可再现的,可以提供一个 seed(种子) 和 field(字段)。
然后,将基于该种子、所考虑文档的 field(字段) 的最小值以及基于索引名称和分片id计算的 盐(salt) 来计算最终得分,以便具有相同值但存储在不同索引中的文档获得不同的得分。
请注意,在同一个分片中并且具有相同 field 值的文档将获得相同的分数,因此通常希望对所有文档使用具有唯一值的字段。
一个好的默认选择可能是使用 _seq_no 字段,其唯一的缺点是如果文档被更新,分数将会改变,因为更新操作也会更新 _seq_no 字段的值。
可以在不设置字段的情况下设置种子,但这已被废弃,因为这需要在 _id 字段上加载 fielddata(字段的数据),这会消耗大量内存。
GET /_search
{
"query": {
"function_score": {
"random_score": {
"seed": 10,
"field": "_seq_no"
}
}
}
}
field_value_factor 函数允许你使用文档中的字段来影响分数。
它类似于使用 script_score 函数,但是它避免了脚本的开销。
如果用于 多值(multi-valued) 字段,则计算中仅使用字段的第一个值。
例如,假设你有一个用数字 likes 字段索引的文档,并希望用该字段影响文档的评分,以下就是一个示例:
GET /_search
{
"query": {
"function_score": {
"field_value_factor": {
"field": "likes",
"factor": 1.2,
"modifier": "sqrt",
"missing": 1
}
}
}
}
上面的代码将转化为以下评分公式:
sqrt(1.2 * doc['likes'].value)
函数 field_value_factor 有多个选项:
|
|
要从文档中提取的字段。 |
|
|
与字段值相乘的可选因子,默认值为 |
|
|
应用于字段值的修饰符,可以是下列值之一: |
| 修饰符 | 意义 |
|---|---|
|
不要对字段值应用任何乘数 |
|
取字段值的常用对数(common logarithm) 。
由于该函数用于 0 到 1 之间的值时会返回负值,这会导致错误,所以建议使用 |
|
将字段值加 1,取常用对数 |
|
将字段值加 2,取常用对数 |
|
取字段值的自然对数(natural logarithm)。
由于该函数用于 0 到 1 之间的值时会返回负值,这会导致错误,因此建议使用 |
|
将字段值加 1,取自然对数 |
|
将字段值加 2,取自然对数 |
|
字段值的平方(乘以它本身) |
|
取字段值的 平方根(square root) |
|
字段值的倒数(reciprocate) ,与 |
-
missing - 文档没有该字段时使用的值。 修饰符和因子仍然应用于它,就好像它是从文档中读取的一样。
field_value_score 函数生成的分数值必须是非负的,否则将会引起错误。
如果 log 和 ln 修饰符用于 0 到 1 之间的值,将产生负值。
确保使用范围过滤器限制字段的值以避免这种情况,或者使用 log1p 和 ln1p。
请记住,取 0 的 log() 或 负数的平方根是非法操作,将会引发异常。
确保使用范围过滤器限制字段的值以避免这种情况,或者使用 log1p 和 ln1p。
衰减函数(decay functions) 使用根据文档的数值字段值与用户给定原点的距离衰减的函数对文档进行评分。 这类似于 范围查询(range query),但是使用平滑的边缘而不是方框。
要对具有数值字段的查询使用距离评分,用户必须为每个字段定义 origin (原点)和 scale(范围)。
需要使用 origin (原点) 来定义计算距离的“中心点”,使用 scale(范围) 来定义衰减率。
衰减函数可以这样定义:
"DECAY_FUNCTION": {
"FIELD_NAME": {
"origin": "11, 12",
"scale": "2km",
"offset": "0km",
"decay": 0.33
}
}
在上面的例子中,字段是 geo_point 类型,origin 可以以 geo 格式提供。
在这种情况下,scale 和 offset 必须使用上例中的单位。
如果你的字段是 date 类型,可以将 scale 和 offset 设置为天(d)、周(w)等。
示例:
GET /_search
{
"query": {
"function_score": {
"gauss": {
"date": {
"origin": "2013-09-17",
"scale": "10d",
"offset": "5d",
"decay" : 0.5
}
}
}
}
}
|
origin 的日期格式取决于 mapping 中定义的 |
|
|
参数 |
|
|
用于计算距离的原点。
对于 numeric 字段,必须以数字形式给出;对于 date 字段,必须以日期形式给出;对于 geo 段,必须以地理点形式给出。
对于 geo 和 numeric 字段是必需的。
对于 date 字段,默认值为 |
|
|
所有类型都需要。
定义从 origin + offset 的距离,在该距离处计算的分数将等于参数 |
|
|
如果定义了 |
|
|
参数 |
在第一个例子中,文档可能表示酒店并包含 geo(地理位置) 字段。 你希望根据酒店离给定位置的距离来计算衰减函数。 你可能不会立即看到为 guass(高斯)函数 选择哪一个 scale,但是你可以这样说:“在距离期望位置 2km 处,分数应减少到三分之一。” 然后将自动调整参数"scale",以确保评分函数计算出距离期望位置 2km 的酒店的分数为0.33。
在第二个例子中,字段值在 2013-09-12 和 2013-09-22 之间的文档的权重(weight)为 1.0,距离该日期超过 15 天的文档的权重为 0.5。
DECAY_FUNCTION 决定衰减的形状:
-
gauss -
正态衰减,计算如下:

其中,要计算
 以确保分数在距离
以确保分数在距离 origin+-offset的scale距离处取值为decay: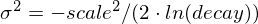
有关
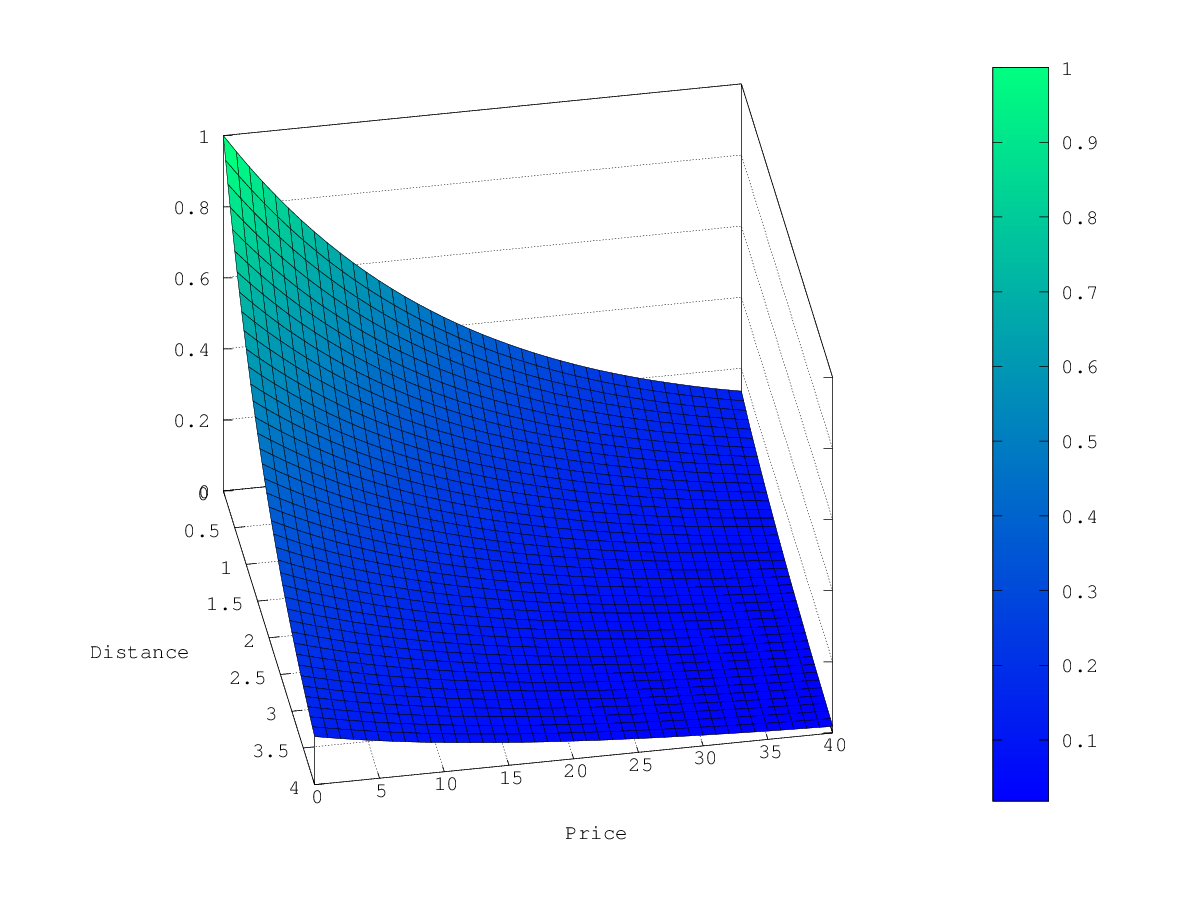
gauss函数生成的曲线的图形的演示,请参考 正态衰减,关键字gauss。 -
exp -
指数衰减,计算如下:

其中,参数
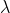 再次被计算以确保分数在距离
再次被计算以确保分数在距离 origin+-offset的scale距离处取值为decay:
有关
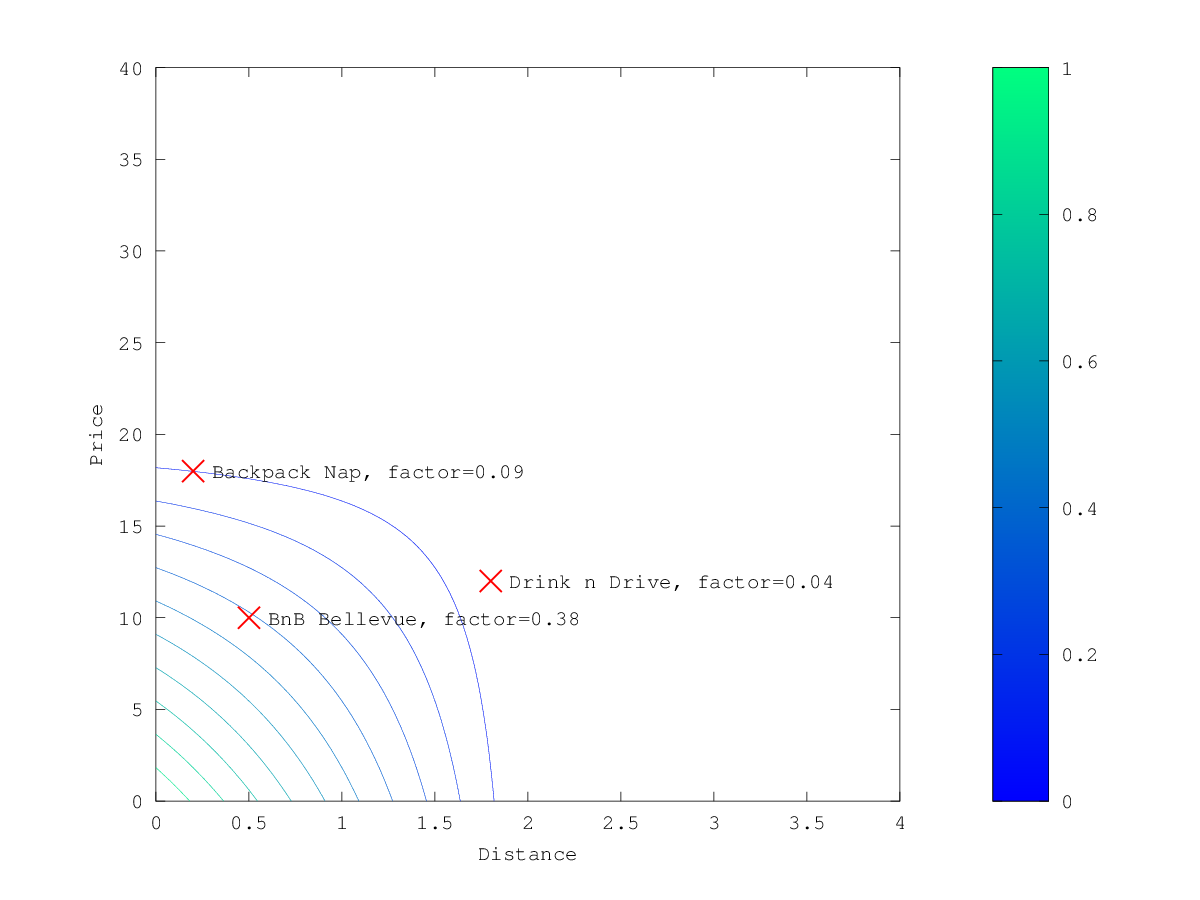
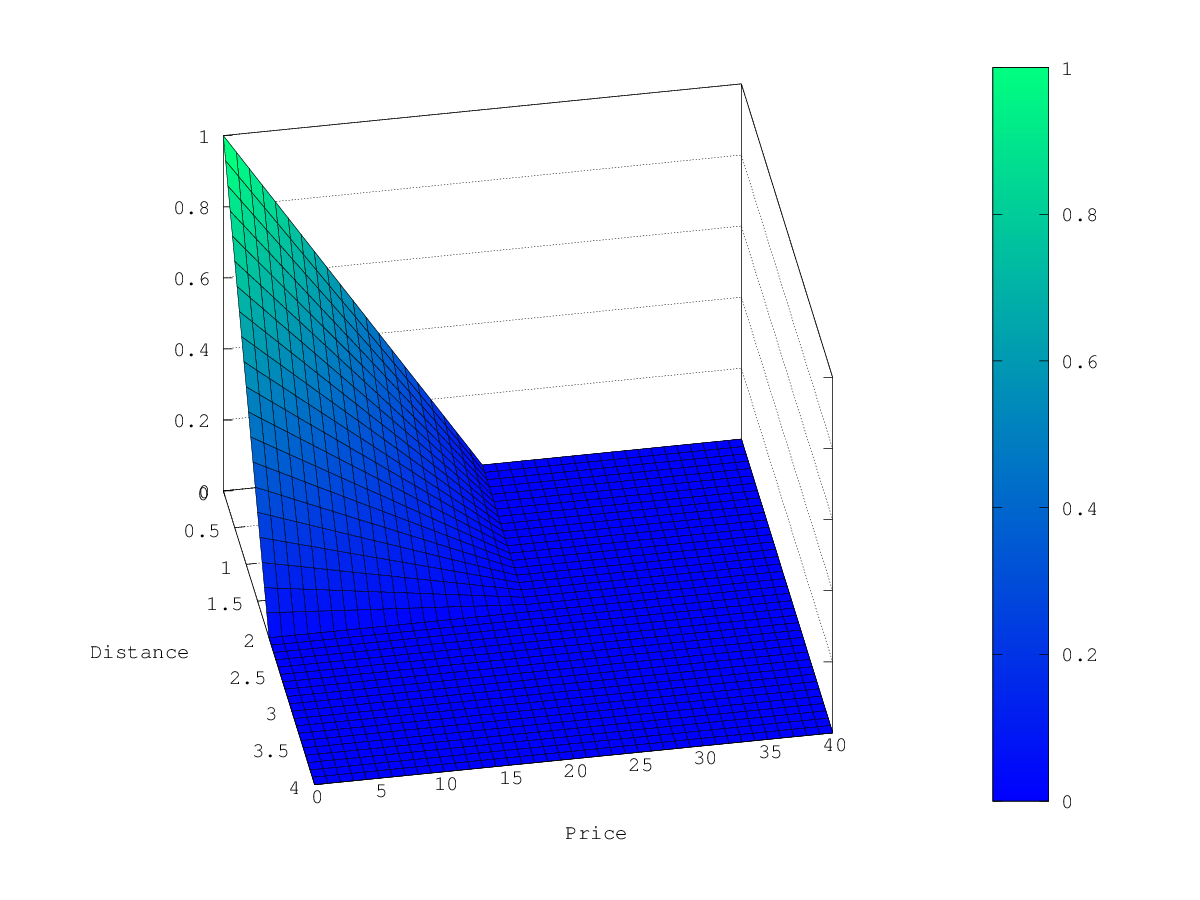
exp函数生成的曲线的图形的演示,请参考 指数衰减,关键字exp。 -
linear -
线性衰减,计算如下:
 .
.其中,参数
s再次被计算以确保分数在距离origin+-offset的scale距离处取值为decay: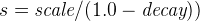
与正态和指数衰减相反,如果字段值超过用户给定 scale 值的两倍,此函数实际上将分数设置为0。
对于单个函数,三个衰减函数以及它们的参数可以像下面这样可视化(在这个例子中称为 “age”(年龄) 的字段):
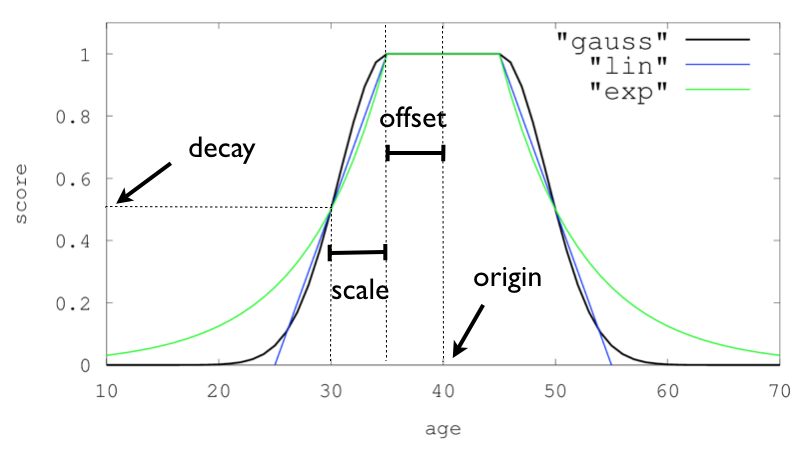
假如你正在某个城市寻找一家酒店,而你的预算有限。 此外,你希望酒店靠近市中心,因此酒店离理想位置越远,入住的可能性就越小。
你希望匹配你的标准(例如,“hotel, Nancy, non-smoker”)的查询结果根据到市中心的距离以及价格进行评分。
直觉上,你可能希望将市中心定义为起点,并且可能愿意从酒店步行 2km 到市中心。
在这种情况下,位置字段的 origin 是城镇中心,scale 为 2km。
如果你的预算很低,你可能更喜欢便宜的东西而不是贵的东西。 对于 price(价格) 字段, origin 为 0 欧元,scale 取决于你愿意支付的金额,例如 20 欧元。
在本例中,对于酒店的价格,字段可能被称为 "price",而对于该酒店的坐标,字段可能被称为 "location"。
在这种情况下, price 的函数是:
对于 location:
假设你想将这两个函数在原始分数上相乘,则请求如下所示:
GET /_search
{
"query": {
"function_score": {
"functions": [
{
"gauss": {
"price": {
"origin": "0",
"scale": "20"
}
}
},
{
"gauss": {
"location": {
"origin": "11, 12",
"scale": "2km"
}
}
}
],
"query": {
"match": {
"properties": "balcony"
}
},
"score_mode": "multiply"
}
}
}
接下来,我们展示了三种可能的衰减函数的计算分数。
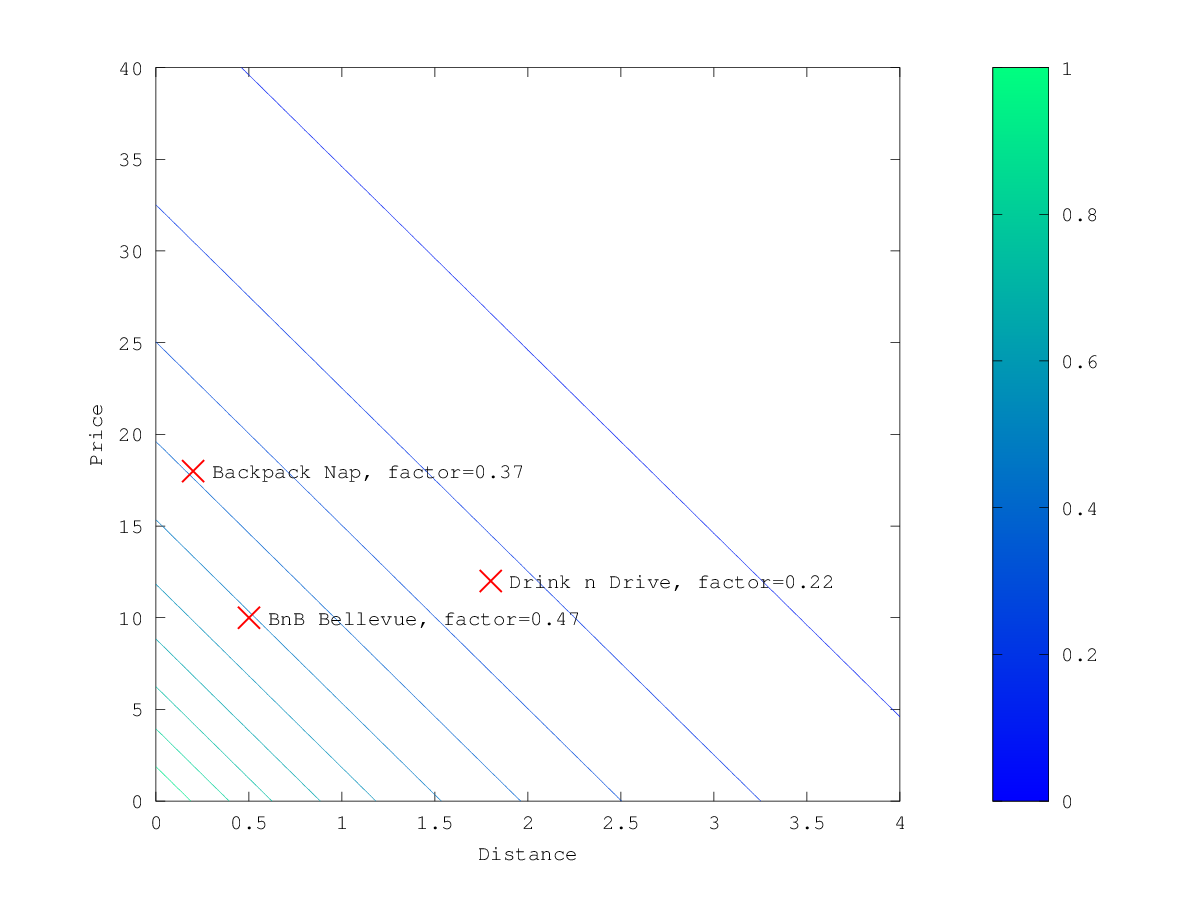
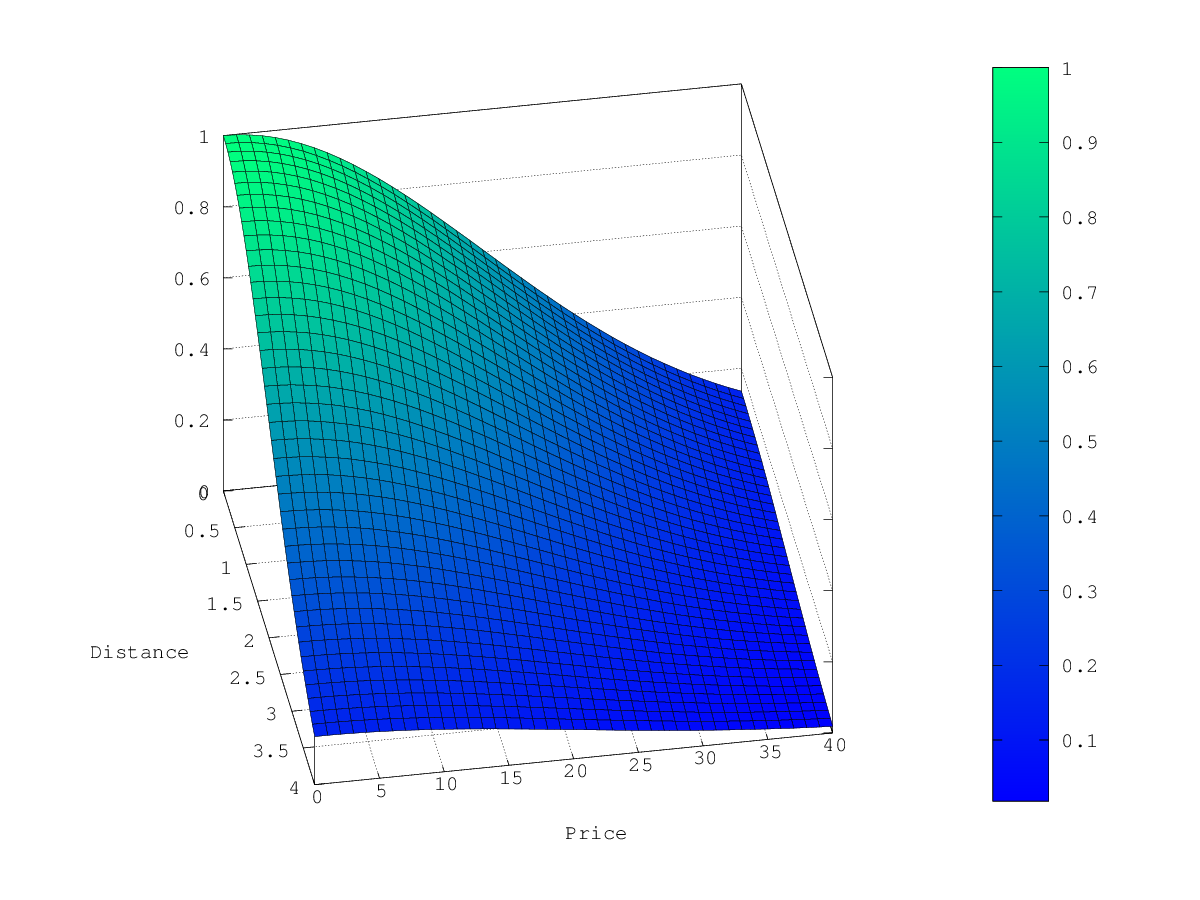
在上面的示例中,当选择 gauss 作为衰减函数时,乘数的等高线和曲面图如下所示:
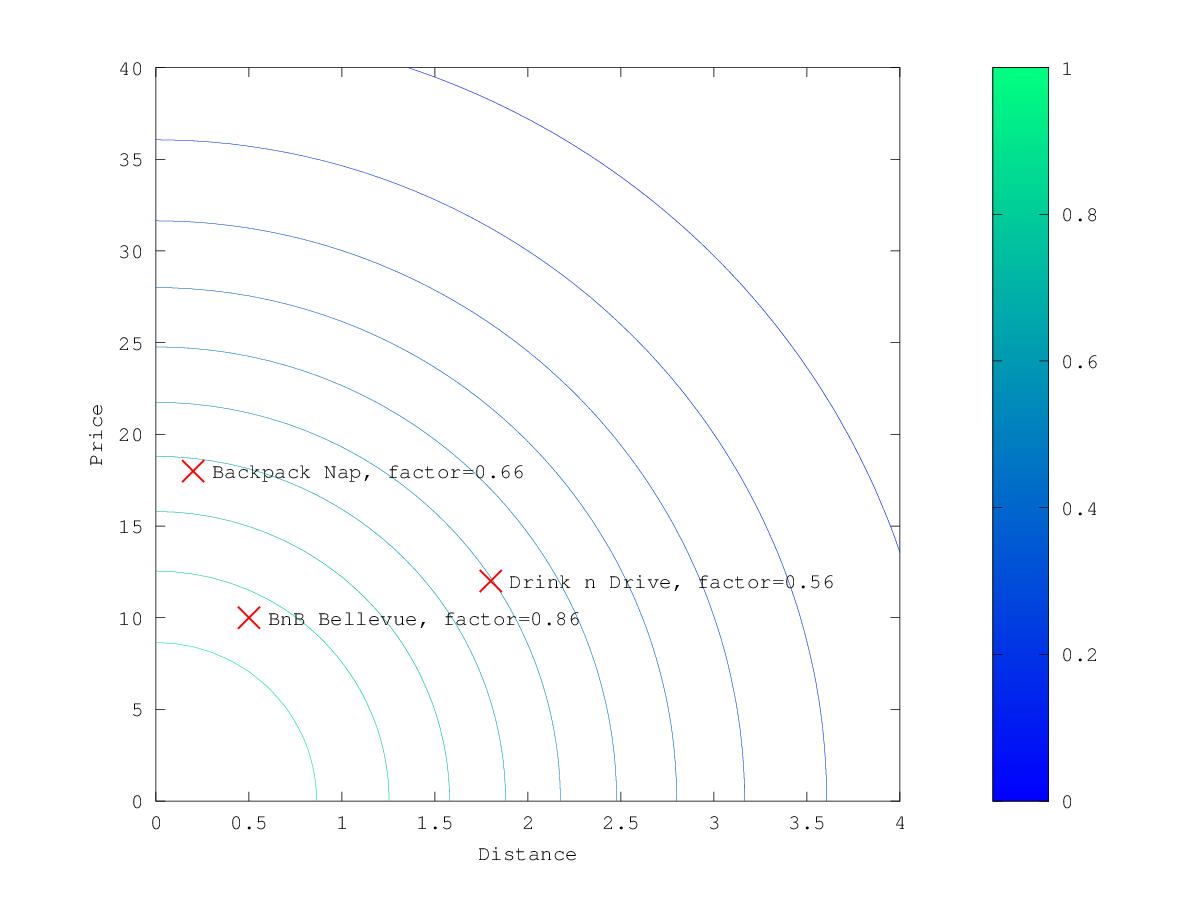
假设原始搜索结果匹配三家酒店:
- "Backback Nap"
- "Drink n Drive"
- "BnB Bellevue"
"Drink n Drive" 离你定义的位置相当远(将近 2km),而且不太便宜(约 13 欧元),所以它的因子很低,为 0.56。 "BnB Bellevue"和"Backback Nap"都非常接近定义的位置,但"BnB Bellevue"更便宜,因此它的因子为 0.86,而"Backpack Nap"的因子值为 0.66。