本地英文版地址: ../en/how-watcher-works.html
How Watcher worksedit
You add watches to automatically perform an action when certain conditions are met. The conditions are generally based on data you’ve loaded into the watch, also known as the Watch Payload. This payload can be loaded from different sources - from Elasticsearch, an external HTTP service, or even a combination of the two.
For example, you could configure a watch to send an email to the sysadmin when a search in the logs data indicates that there are too many 503 errors in the last 5 minutes.
This topic describes the elements of a watch and how watches operate.
Watch definitionedit
A watch consists of a trigger, input, condition, and actions. The actions define what needs to be done once the condition is met. In addition, you can define conditions and transforms to process and prepare the watch payload before executing the actions.
- Trigger
- Determines when the watch is checked. A watch must have a trigger.
- Input
- Loads data into the watch payload. If no input is specified, an empty payload is loaded.
- Condition
-
Controls whether the watch actions are executed. If no condition is specified,
the condition defaults to
always. - Transform
- Processes the watch payload to prepare it for the watch actions. You can define transforms at the watch level or define action-specific transforms. Optional.
- Actions
- Specify what happens when the watch condition is met.
For example, the following snippet shows a put watch request that defines a watch that looks for log error events:
PUT _watcher/watch/log_errors
{
"metadata" : {
"color" : "red"
},
"trigger" : {
"schedule" : {
"interval" : "5m"
}
},
"input" : {
"search" : {
"request" : {
"indices" : "log-events",
"body" : {
"size" : 0,
"query" : { "match" : { "status" : "error" } }
}
}
}
},
"condition" : {
"compare" : { "ctx.payload.hits.total.value" : { "gt" : 5 }}
},
"transform" : {
"search" : {
"request" : {
"indices" : "log-events",
"body" : {
"query" : { "match" : { "status" : "error" } }
}
}
}
},
"actions" : {
"my_webhook" : {
"webhook" : {
"method" : "POST",
"host" : "mylisteninghost",
"port" : 9200,
"path" : "/{{watch_id}}",
"body" : "Encountered {{ctx.payload.hits.total.value}} errors"
}
},
"email_administrator" : {
"email" : {
"to" : "sys.admino@host.domain",
"subject" : "Encountered {{ctx.payload.hits.total.value}} errors",
"body" : "Too many error in the system, see attached data",
"attachments" : {
"attached_data" : {
"data" : {
"format" : "json"
}
}
},
"priority" : "high"
}
}
}
}
|
Metadata - You can attach optional static metadata to a watch. |
|
|
Trigger - This schedule trigger executes the watch every 5 minutes. |
|
|
Input - This input searches for errors in the |
|
|
Condition - This condition checks to see if there are more than 5 error
events (hits in the search response). If there are, execution
continues for all |
|
|
Transform - If the watch condition is met, this transform loads all of the
errors into the watch payload by searching for the errors using
the default search type, |
|
|
Actions - This watch has two actions. The |
Watch executionedit
When you add a watch, Watcher immediately registers its trigger with the
appropriate trigger engine. Watches that have a schedule trigger are
registered with the scheduler trigger engine.
The scheduler tracks time and triggers watches according to their schedules.
On each node, that contains one of the .watches shards, a scheduler, that is
bound to the watcher lifecycle runs. Even though all primaries and replicas are
taken into account, when a watch is triggered, watcher also ensures, that each
watch is only triggered on one of those shards. The more replica shards you
add, the more distributed the watches can be executed. If you add or remove
replicas, all watches need to be reloaded. If a shard is relocated, the
primary and all replicas of this particular shard will reload.
Because the watches are executed on the node, where the watch shards are, you can create dedicated watcher nodes by using shard allocation filtering.
You could configure nodes with a dedicated node.attr.role: watcher property and
then configure the .watches index like this:
PUT .watches/_settings
{
"index.routing.allocation.include.role": "watcher"
}
When the Watcher service is stopped, the scheduler stops with it. Trigger engines use a separate thread pool from the one used to execute watches.
When a watch is triggered, Watcher queues it up for execution. A watch_record
document is created and added to the watch history and the watch’s status is set
to awaits_execution.
When execution starts, Watcher creates a watch execution context for the watch. The execution context provides scripts and templates with access to the watch metadata, payload, watch ID, execution time, and trigger information. For more information, see Watch Execution Context.
During the execution process, Watcher:
- Loads the input data as the payload in the watch execution context. This makes the data available to all subsequent steps in the execution process. This step is controlled by the input of the watch.
-
Evaluates the watch condition to determine whether or not to continue processing
the watch. If the condition is met (evaluates to
true), processing advances to the next step. If it is not met (evaluates tofalse), execution of the watch stops. - Applies transforms to the watch payload (if needed).
- Executes the watch actions granted the condition is met and the watch is not throttled.
When the watch execution finishes, the execution result is recorded as a Watch Record in the watch history. The watch record includes the execution time and duration, whether the watch condition was met, and the status of each action that was executed.
The following diagram shows the watch execution process:
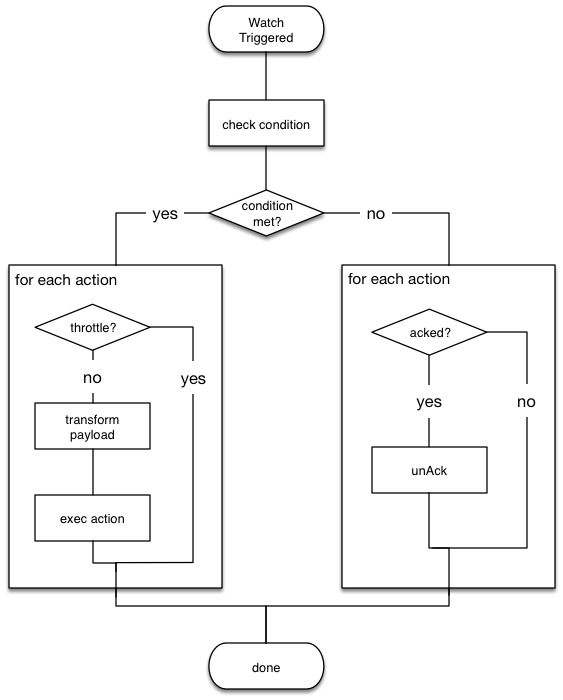
Watch acknowledgment and throttlingedit
Watcher supports both time-based and acknowledgment-based throttling. This enables you to prevent actions from being repeatedly executed for the same event.
By default, Watcher uses time-based throttling with a throttle period of 5 seconds. This means that if a watch is executed every second, its actions are performed a maximum of once every 5 seconds, even when the condition is always met. You can configure the throttle period on a per-action basis or at the watch level.
Acknowledgment-based throttling enables you to tell Watcher not to send any more
notifications about a watch as long as its condition is met. Once the condition
evaluates to false, the acknowledgment is cleared and Watcher resumes executing
the watch actions normally.
For more information, see Acknowledgement and throttling.
Watch active stateedit
By default, when you add a watch it is immediately set to the active state, registered with the appropriate trigger engine, and executed according to its configured trigger.
You can also set a watch to the inactive state. Inactive watches are not registered with a trigger engine and can never be triggered.
To set a watch to the inactive state when you create it, set the
active parameter to inactive. To
deactivate an existing watch, use the
deactivate watch API. To reactivate an
inactive watch, use the
activate watch API.
You can use the execute watch API to force the execution of a watch even when it is inactive.
Deactivating watches is useful in a variety of situations. For example, if you have a watch that monitors an external system and you need to take that system down for maintenance, you can deactivate the watch to prevent it from falsely reporting availability issues during the maintenance window.
Deactivating a watch also enables you to keep it around for future use without deleting it from the system.
Scripts and templatesedit
You can use scripts and templates when defining a watch. Scripts and templates can reference elements in the watch execution context, including the watch payload. The execution context defines variables you can use in a script and parameter placeholders in a template.
Watcher uses the Elasticsearch script infrastructure, which supports inline and stored. Scripts and templates are compiled and cached by Elasticsearch to optimize recurring execution. Autoloading is also supported. For more information, see Scripting and How to use scripts.
Watch execution contextedit
The following snippet shows the basic structure of the Watch Execution Context:
{
"ctx" : {
"metadata" : { ... },
"payload" : { ... },
"watch_id" : "<id>",
"execution_time" : "20150220T00:00:10Z",
"trigger" : {
"triggered_time" : "20150220T00:00:10Z",
"scheduled_time" : "20150220T00:00:00Z"
},
"vars" : { ... }
}
|
Any static metadata specified in the watch definition. |
|
|
The current watch payload. |
|
|
The id of the executing watch. |
|
|
A timestamp that shows when the watch execution started. |
|
|
Information about the trigger event. For a |
|
|
Dynamic variables that can be set and accessed by different constructs during the execution. These variables are scoped to a single execution (i.e they’re not persisted and can’t be used between different executions of the same watch) |
Using scriptsedit
You can use scripts to define conditions and transforms. The default scripting language is Painless.
Starting with 5.0, Elasticsearch is shipped with the new Painless scripting language. Painless was created and designed specifically for use in Elasticsearch. Beyond providing an extensive feature set, its biggest trait is that it’s properly sandboxed and safe to use anywhere in the system (including in Watcher) without the need to enable dynamic scripting.
Scripts can reference any of the values in the watch execution context or values explicitly passed through script parameters.
For example, if the watch metadata contains a color field
(e.g. "metadata" : {"color": "red"}), you can access its value with the via the
ctx.metadata.color variable. If you pass in a color parameter as part of the
condition or transform definition (e.g. "params" : {"color": "red"}), you can
access its value via the color variable.
Using templatesedit
You use templates to define dynamic content for a watch. At execution time,
templates pull in data from the watch execution context. For example, you can use
a template to populate the subject field for an email action with data stored
in the watch payload. Templates can also access values explicitly passed through
template parameters.
You specify templates using the Mustache scripting language.
For example, the following snippet shows how templates enable dynamic subjects in sent emails:
{
"actions" : {
"email_notification" : {
"email" : {
"subject" : "{{ctx.metadata.color}} alert"
}
}
}
}
Inline templates and scriptsedit
To define an inline template or script, you simply specify it directly in the
value of a field. For example, the following snippet configures the subject of
the email action using an inline template that references the color value in
the context metadata.
"actions" : {
"email_notification" : {
"email" : {
"subject" : "{{ctx.metadata.color}} alert"
}
}
}
}
For a script, you simply specify the inline script as the value of the script
field. For example:
"condition" : {
"script" : "return true"
}
You can also explicitly specify the inline type by using a formal object definition as the field value. For example:
"actions" : {
"email_notification" : {
"email" : {
"subject" : {
"source" : "{{ctx.metadata.color}} alert"
}
}
}
}
The formal object definition for a script would be:
"condition" : {
"script" : {
"source": "return true"
}
}
Stored templates and scriptsedit
If you store your templates and scripts, you can reference them by id.
To reference a stored script or template, you use the formal object definition
and specify its id in the id field. For example, the following snippet
references the email_notification_subject template:
{
...
"actions" : {
"email_notification" : {
"email" : {
"subject" : {
"id" : "email_notification_subject",
"params" : {
"color" : "red"
}
}
}
}
}
}