本地英文版地址: ../en/search-aggregations-pipeline-serialdiff-aggregation.html
序列差分是一种技术,时间序列中的值在不同的时间延迟或周期中被减去。 例如,数据点 f(x) = f(xt) - f(xt-n),其中n是使用的周期。
周期为1相当于没有时间归一化的导数:它只是从一个点到下一个点的变化。 单周期对于去除固定值的线性趋势很有用。
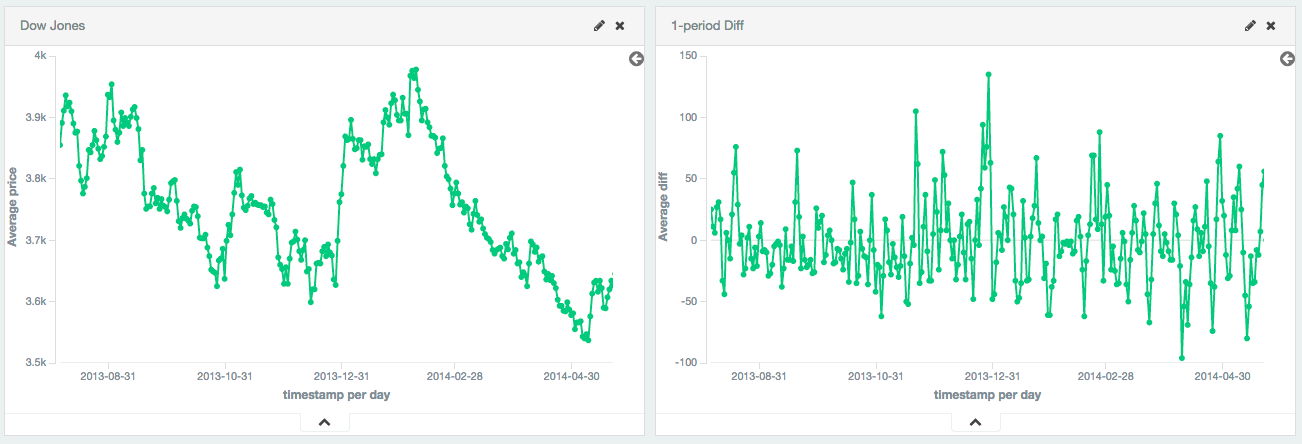
单周期对于将数据转换为平稳序列也很有用。 在这个例子中,道琼斯指数(Dow Jones)是在大约250天内绘制的。 原始数据不是固定的,这使得一些技术很难使用。
通过计算第一差值,我们对数据进行去趋势化处理(例如,去除一个固定值的线性趋势)。 我们可以看到,数据变成了一个平稳的序列(例如,第一个差异随机分布在零附近,似乎没有表现出任何模式/行为)。 这个转换显示出数据集呈随机游走分布状态; 该值是前一个值+/-一个随机量。 这种洞察力允许选择进一步的分析工具。
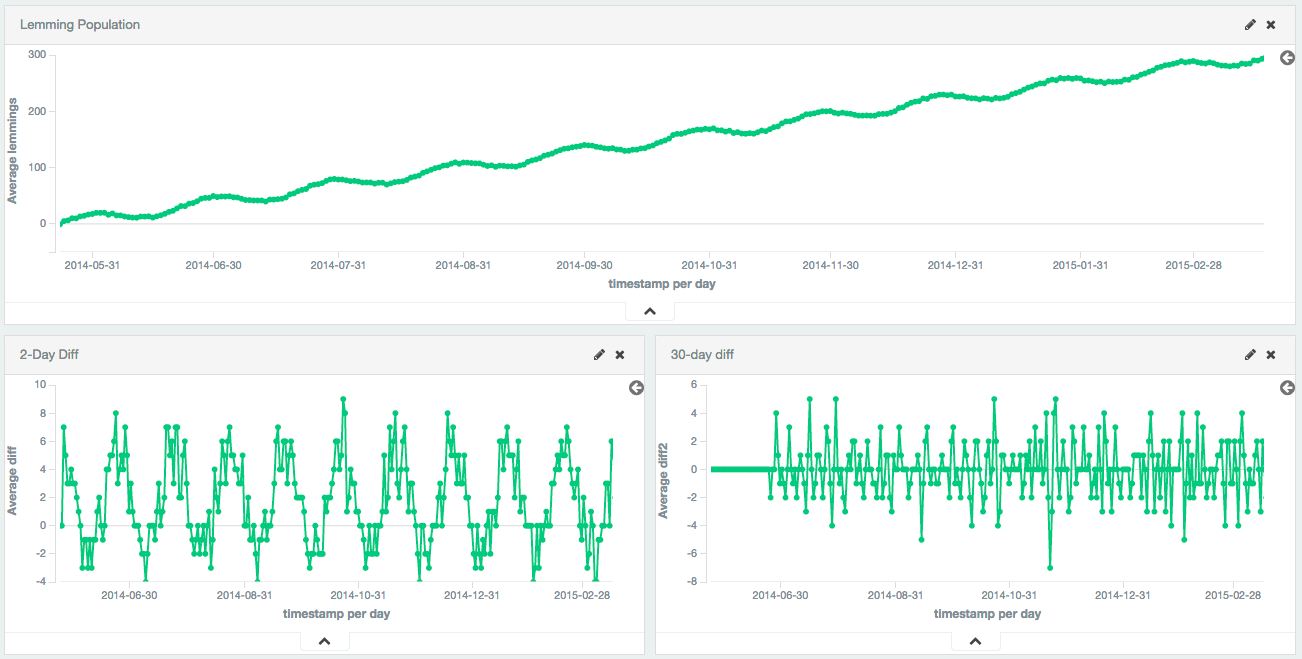
更长的周期可用于移除季节性/周期性行为。 在这个例子中,一群旅鼠是用正弦波+固定线性趋势+随机噪声合成生成的。 正弦波的周期为30天。
第一个差异去除了固定趋势,只留下一个正弦波。 然后将第30次差应用于第1次差,以消除循环行为,留下一个可用于其他分析的平稳序列。
一个单独的serial_diff看起来像这样:
{
"serial_diff": {
"buckets_path": "the_sum",
"lag": "7"
}
}
表 29. serial_diff参数
| 参数名称 | 描述 | 是否必需 | 默认值 |
|---|---|---|---|
|
感兴趣的度量的路径 (更多详情请参考 |
必需 |
|
|
要从当前值中减去的历史桶。 例如,滞后7将从7个桶之前的值中减去当前值。 必须是非零正整数 |
可选 |
|
|
确定当遇到数据中的间隙时应该发生什么。 |
可选 |
|
|
应用于此聚合的输出值的格式 |
可选 |
|
serial_diff聚合必须嵌入一个histogram或date_histogram聚合中:
POST /_search
{
"size": 0,
"aggs": {
"my_date_histo": {
"date_histogram": {
"field": "timestamp",
"calendar_interval": "day"
},
"aggs": {
"the_sum": {
"sum": {
"field": "lemmings"
}
},
"thirtieth_difference": {
"serial_diff": {
"buckets_path": "the_sum",
"lag" : 30
}
}
}
}
}
}
|
一个名为“my_date_histo”的 |
|
|
|
|
|
最后,我们指定一个 |
序列差分的构建,首先要指定一个字段的histogram或date_histogram聚合。
然后,你可以选择在那个直方图中添加普通的度量,如sum。
最后,serial_diff被嵌入直方图中。
然后,buckets_path参数用于“指向”直方图内的一个同级度量(有关buckets_path语法的描述,请参见buckets_path语法)。