WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Replica Shardsedit
Up until now we have spoken only about primary shards, but we have another tool in our belt: replica shards. The main purpose of replicas is for failover, as discussed in Life Inside a Cluster: if the node holding a primary shard dies, a replica is promoted to the role of primary.
At index time, a replica shard does the same amount of work as the primary shard. New documents are first indexed on the primary and then on any replicas. Increasing the number of replicas does not change the capacity of the index.
However, replica shards can serve read requests. If, as is often the case, your index is search heavy, you can increase search performance by increasing the number of replicas, but only if you also add extra hardware.
Let’s return to our example of an index with two primary shards. We increased capacity of the index by adding a second node. Adding more nodes would not help us to add indexing capacity, but we could take advantage of the extra hardware at search time by increasing the number of replicas:
PUT /my_index/_settings
{
"number_of_replicas": 1
}
Having two primary shards, plus a replica of each primary, would give us a total of four shards: one for each node, as shown in Figure 51, “An index with two primary shards and one replica can scale out across four nodes”.
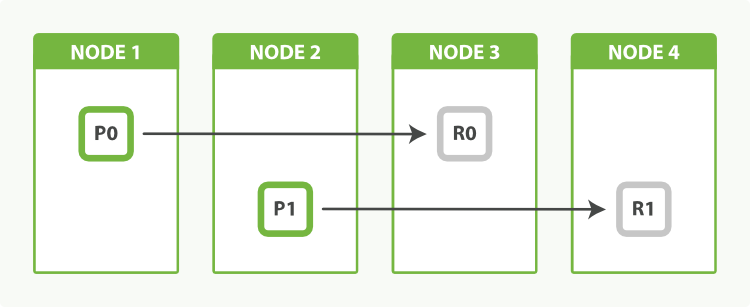
Balancing Load with Replicasedit
Search performance depends on the response times of the slowest node, so it is a good idea to try to balance out the load across all nodes. If we added just one extra node instead of two, we would end up with two nodes having one shard each, and one node doing double the work with two shards.
We can even things out by adjusting the number of replicas. By allocating two replicas instead of one, we end up with a total of six shards, which can be evenly divided between three nodes, as shown in Figure 52, “Adjust the number of replicas to balance the load between nodes”:
PUT /my_index/_settings
{
"number_of_replicas": 2
}
As a bonus, we have also increased our availability. We can now afford to lose two nodes and still have a copy of all our data.
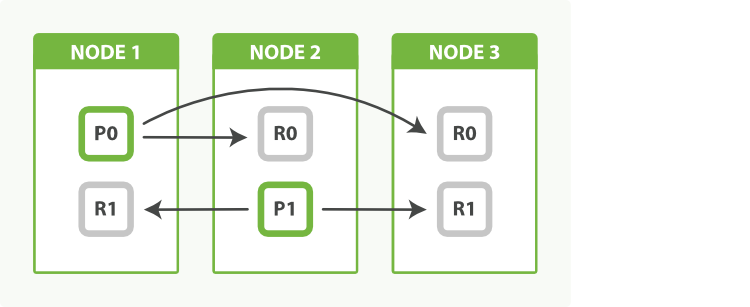
The fact that node 3 holds two replicas and no primaries is not important. Replicas and primaries do the same amount of work; they just play slightly different roles. There is no need to ensure that primaries are distributed evenly across all nodes.