WARNING: The 2.x versions of Elasticsearch have passed their EOL dates. If you are running a 2.x version, we strongly advise you to upgrade.
This documentation is no longer maintained and may be removed. For the latest information, see the current Elasticsearch documentation.
Pluggable Similarity Algorithmsedit
Before we move on from relevance and scoring, we will finish this chapter with a more advanced subject: pluggable similarity algorithms. While Elasticsearch uses the Lucene’s Practical Scoring Function as its default similarity algorithm, it supports other algorithms out of the box, which are listed in the Similarity Modules documentation.
Okapi BM25edit
The most interesting competitor to TF/IDF and the vector space model is called Okapi BM25, which is considered to be a state-of-the-art ranking function. BM25 originates from the probabilistic relevance model, rather than the vector space model, yet the algorithm has a lot in common with Lucene’s practical scoring function.
Both use term frequency, inverse document frequency, and field-length normalization, but the definition of each of these factors is a little different. Rather than explaining the BM25 formula in detail, we will focus on the practical advantages that BM25 offers.
Term-frequency saturationedit
Both TF/IDF and BM25 use inverse document frequency to distinguish between common (low value) words and uncommon (high value) words. Both also recognize (see Term frequency) that the more often a word appears in a document, the more likely is it that the document is relevant for that word.
However, common words occur commonly. The fact that a common word appears many times in one document is offset by the fact that the word appears many times in all documents.
However, TF/IDF was designed in an era when it was standard practice to remove the most common words (or stopwords, see Stopwords: Performance Versus Precision) from the index altogether. The algorithm didn’t need to worry about an upper limit for term frequency because the most frequent terms had already been removed.
In Elasticsearch, the standard analyzer—the default for string fields—doesn’t remove stopwords because, even though they are words of little
value, they do still have some value. The result is that, for very long
documents, the sheer number of occurrences of words like the and and can
artificially boost their weight.
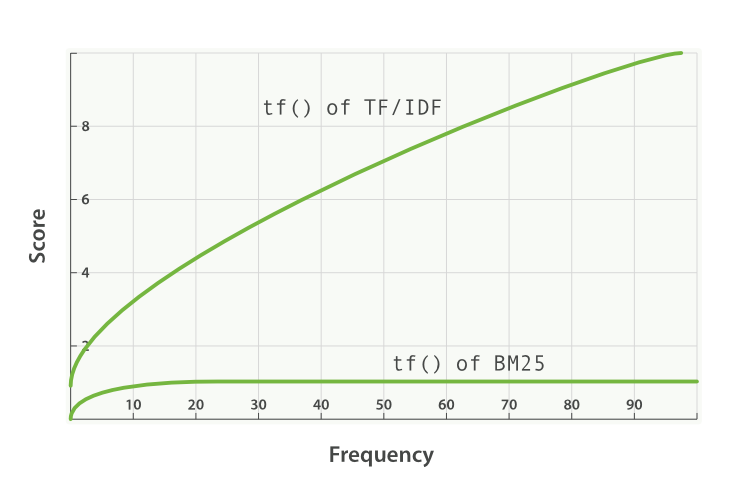
BM25, on the other hand, does have an upper limit. Terms that appear 5 to 10 times in a document have a significantly larger impact on relevance than terms that appear just once or twice. However, as can be seen in Figure 34, “Term frequency saturation for TF/IDF and BM25”, terms that appear 20 times in a document have almost the same impact as terms that appear a thousand times or more.
This is known as nonlinear term-frequency saturation.
Field-length normalizationedit
In Field-length norm, we said that Lucene considers shorter fields to have
more weight than longer fields: the frequency of a term in a field is offset
by the length of the field. However, the practical scoring function treats
all fields in the same way. It will treat all title fields (because they
are short) as more important than all body fields (because they are long).
BM25 also considers shorter fields to have more weight than longer fields, but
it considers each field separately by taking the average length of the field
into account. It can distinguish between a short title field and a long
title field.
In Query-Time Boosting, we said that the title field has a
natural boost over the body field because of its length. This natural
boost disappears with BM25 as differences in field length apply only within a
single field.
Tuning BM25edit
One of the nice features of BM25 is that, unlike TF/IDF, it has two parameters that allow it to be tuned:
-
k1 -
This parameter controls how quickly an increase in term frequency results
in term-frequency saturation. The default value is
1.2. Lower values result in quicker saturation, and higher values in slower saturation. -
b -
This parameter controls how much effect field-length normalization should
have. A value of
0.0disables normalization completely, and a value of1.0normalizes fully. The default is0.75.
The practicalities of tuning BM25 are another matter. The default values for
k1 and b should be suitable for most document collections, but the
optimal values really depend on the collection. Finding good values for your
collection is a matter of adjusting, checking, and adjusting again.