英文版地址: https://www.elastic.co/guide/en/elasticsearch/guide/current/merge-process.html
本书基于 Elasticsearch 2.x 版本,有些内容可能已经过时。
段合并edit
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。
段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。
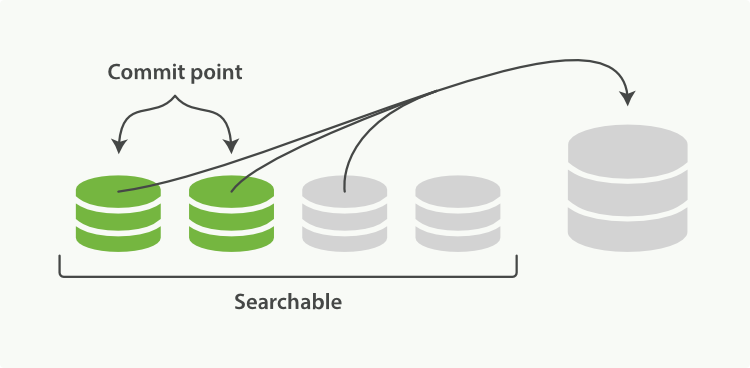
启动段合并不需要你做任何事。进行索引和搜索时会自动进行。这个流程像在 Figure 25, “两个提交了的段和一个未提交的段正在被合并到一个更大的段” 中提到的一样工作:
1、 当索引的时候,刷新(refresh)操作会创建新的段并将段打开以供搜索使用。
2、 合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中。这并不会中断索引和搜索。
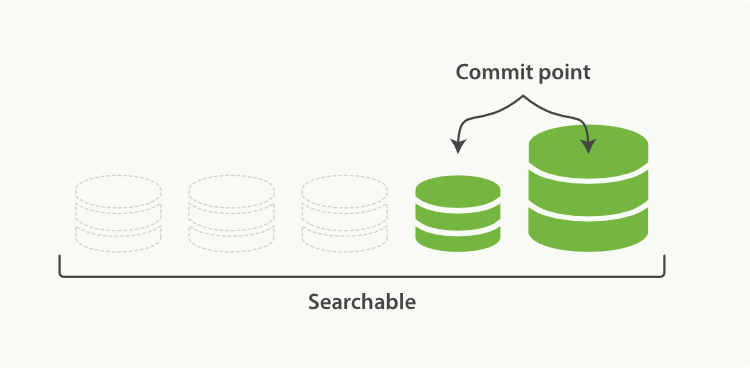
3、 Figure 26, “一旦合并结束,老的段被删除” 说明合并完成时的活动:
- 新的段被刷新(flush)到了磁盘。 ** 写入一个包含新段且排除旧的和较小的段的新提交点。
- 新的段被打开用来搜索。
- 老的段被删除。
合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然 有足够的资源很好地执行。
查看 段和合并 来为你的实例获取关于合并调整的建议。
optimize APIedit
optimize API大可看做是 强制合并 API。它会将一个分片强制合并到 max_num_segments 参数指定大小的段数目。
这样做的意图是减少段的数量(通常减少到一个),来提升搜索性能。
optimize API 不应该 被用在一个活跃的索引————一个正积极更新的索引。后台合并流程已经可以很好地完成工作。
optimizing 会阻碍这个进程。不要干扰它!
在特定情况下,使用 optimize API 颇有益处。例如在日志这种用例下,每天、每周、每月的日志被存储在一个索引中。
老的索引实质上是只读的;它们也并不太可能会发生变化。
在这种情况下,使用optimize优化老的索引,将每一个分片合并为一个单独的段就很有用了;这样既可以节省资源,也可以使搜索更加快速:
请注意,使用 optimize API 触发段合并的操作不会受到任何资源上的限制。这可能会消耗掉你节点上全部的I/O资源, 使其没有余裕来处理搜索请求,从而有可能使集群失去响应。
如果你想要对索引执行 optimize,你需要先使用分片分配(查看 迁移旧索引)把索引移到一个安全的节点,再执行。